




chrome浏览器获取 xpath规则教程
发表:DESTOON模板堂(dtmoban.com)
发表时间:2020-01-15
第一步:
用chrome浏览器打开要采集的网站,
鼠标移动到要采集的内容上

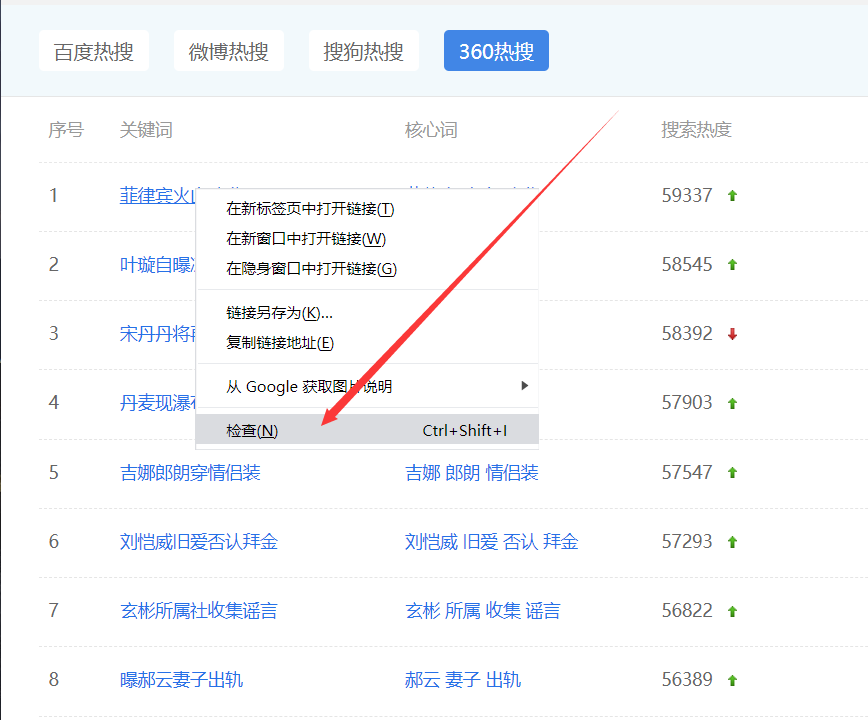
第二步:
鼠标点击右健,选择检查,有些版本是查看元素
第三步
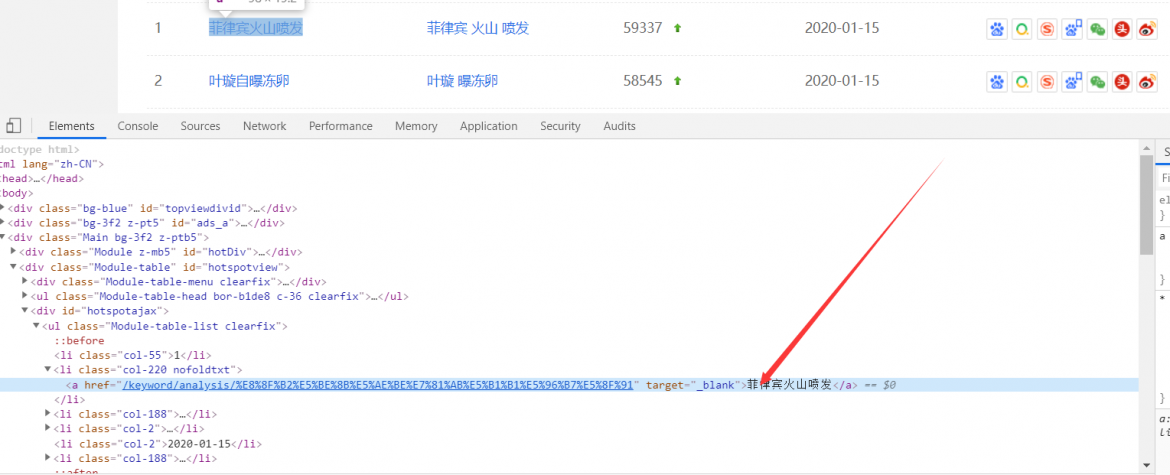
在弹出来的控制台中,选择当前选择位置的代码,然后右健,选择 Copy --- Copy XPath
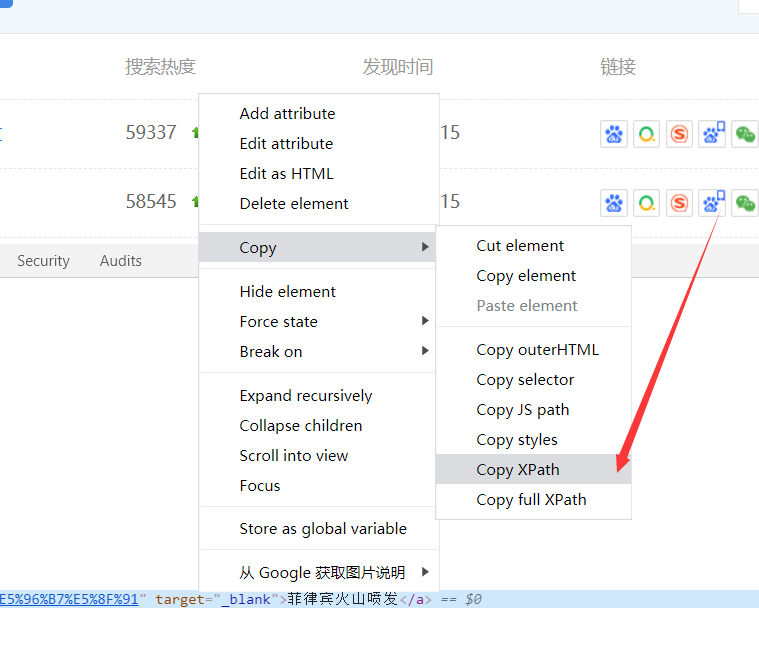
第四步: 把剪贴版里的内容粘贴 即可
第五步:
比如我们当前复制的XPath规则是 //*[@id="hotspotajax"]/ul[1]/li[2]/a
如果这个规则不作任务修改,会发现采集回来的只有第一条信息,但是我们需要的整个列表的信息
通过查看源代码我们发现,列表循环是 ul
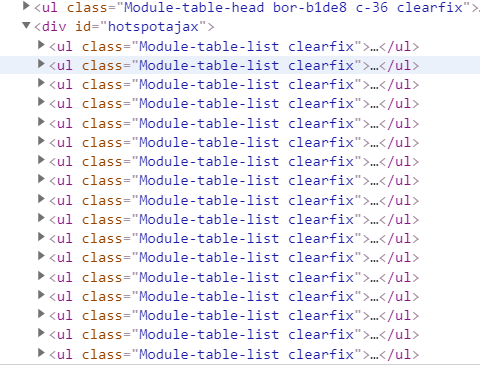
而我们的规则
//*[@id="hotspotajax"]/ul[1]/li[2]/a
ul 后面有一个 [1], 表示只采集第一个ul
要采集列表只需要把 [1]删除即可
//*[@id="hotspotajax"]/ul/li[2]/a
用chrome浏览器打开要采集的网站,
鼠标移动到要采集的内容上
第二步:
鼠标点击右健,选择检查,有些版本是查看元素
第三步
在弹出来的控制台中,选择当前选择位置的代码,然后右健,选择 Copy --- Copy XPath
第四步: 把剪贴版里的内容粘贴 即可
第五步:
比如我们当前复制的XPath规则是 //*[@id="hotspotajax"]/ul[1]/li[2]/a
如果这个规则不作任务修改,会发现采集回来的只有第一条信息,但是我们需要的整个列表的信息
通过查看源代码我们发现,列表循环是 ul
而我们的规则
//*[@id="hotspotajax"]/ul[1]/li[2]/a
ul 后面有一个 [1], 表示只采集第一个ul
要采集列表只需要把 [1]删除即可
//*[@id="hotspotajax"]/ul/li[2]/a
